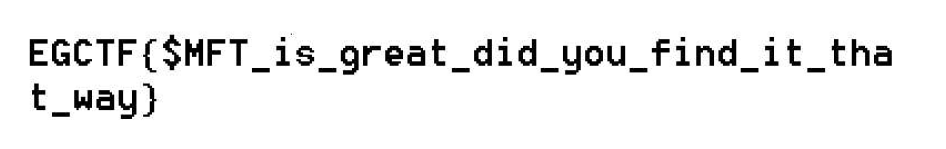Initials
In that challenge we got a .vhd file (Virtual Hard Disk)
Running file on the file we got that result of file command on the vhd file

So it's a NTFS corrupted image so let's try to mount it and fix it with chkdsk
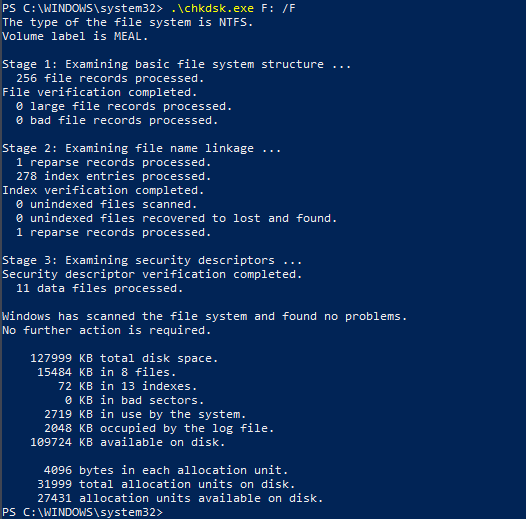
So let's check the files in the image

We only got a pdf file, I spent some time examining the pdf, I thought it might contain something hidden in it but that wasn't the case and I was stuck.
First Hint
don't use automated tools it will damage the file
So I think we shouldn't have used chkdsk it probably corrupted the challenge so I downloaded a fresh copy and I opened the image with the autopsy tool let's see what we got.

Ok, so autopsy craved 6 deleted files the 2 pdfs and the jpeg aren't important.
What matters here are those MFT records, we have 3 user files those files are deleted and we want to recover them.
data.txtlaunch.rarlaunch.bak7204.32481
First we need to know the difference between resident and non-resident files.
Resident and Non-Resident files
When a file's attributes can fit within the MFT file record, they are called resident attributes. For example, information such as filename and time stamp are always included in the MFT file record.
When all of the information for a file is too large to fit in the MFT file record, some of its attributes are nonresident. The nonresident attributes are allocated one or more clusters of disk space elsewhere in the volume.
data.txtis a resident file because it's less than 512kb and it's data can fit into the $MFT record.launch.bak7204.32481is a Non-Resident file and that's the file we need to recover but because it too large to fit in the $MFT record so we will extract it manually but first we need to understand the NTFS structure and the $MFT attributes.
NTFS Baiscs
When you format an NTFS volume, the format program allocates the first 16 sectors for the boot sector and the bootstrap code.
So now we will open the image in FTK-Imager and use it's embedded hex editor to go into the partition boot sector but first we run fdisk -l ch1.vhd to get some information that we will need.
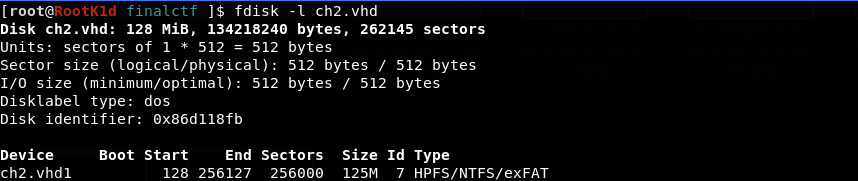
So we got that:
- block size = 512 bytes = 0x200 in hex
- beginning of the partition = 128 block = 0x80 in hex
Let's calculate the offset of the beginning of the partition, since it starts at 0x80 block and we know that the block size is 0x200 so offset = 0x80 * 0x200 = 0x10000
Now let's jump to that offset
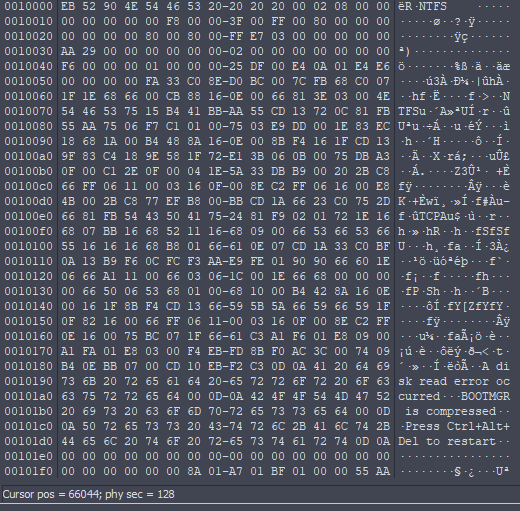
According to the following table we're gonna extract some information from the partition boot sector
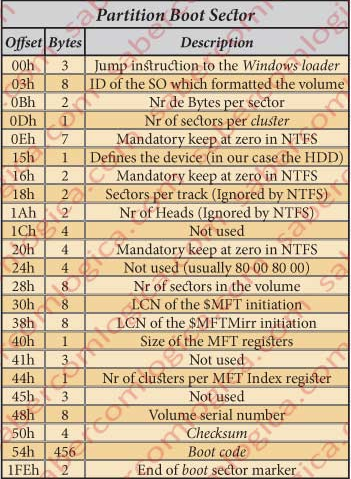
- At offset
1000Dwe got number of blocks per cluster→ 0x08 - At offset
10030we got the start of the $MFT → 0x29AA in clusters
So with this information we got everything we need to jump to the $MFT
- Block size =
0x200 - Beginning of the partition =
0x10000 - Cluster size = 0x08 * 0x200 =
0x1000 - Beginning of the $MFT = 0x29AA * 0x1000 + 0x10000 =
0x29BA000(we multiply by 0x1000 because the MFT starts at cluster 0x29AA and the cluster size is 0x1000 and we then add the result to 0x10000 because that's the start of the partition and all the offsets are relevant to that position)
MFT
Each file on an NTFS volume is represented by a record in a special file called the master file table (MFT). NTFS reserves the first 16 records of the table for special information.
The first record of this table describes the master file table itself, followed by a MFT mirror record.
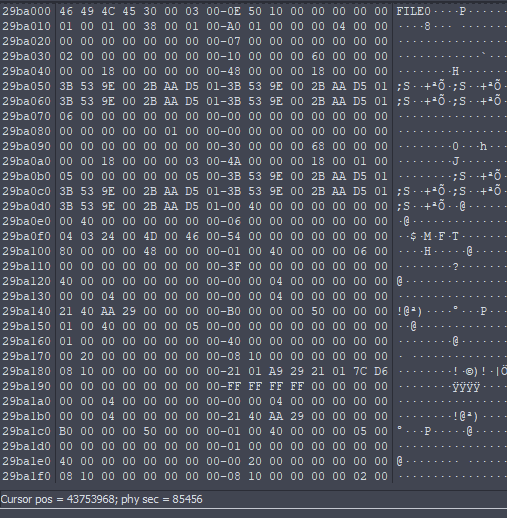
That's the first record of the $MFT it contains the record about the $MFT itself.
We want to jump to the record of our desired file.
If a file is deleted from disk it's data remains there on the disk until it got overwritten and since the MFT contains all the file records we can recover deleted files if they not overwritten.
So let's use MFTParser to get all the MFT records
volatility -f ch1.vhd mftparser
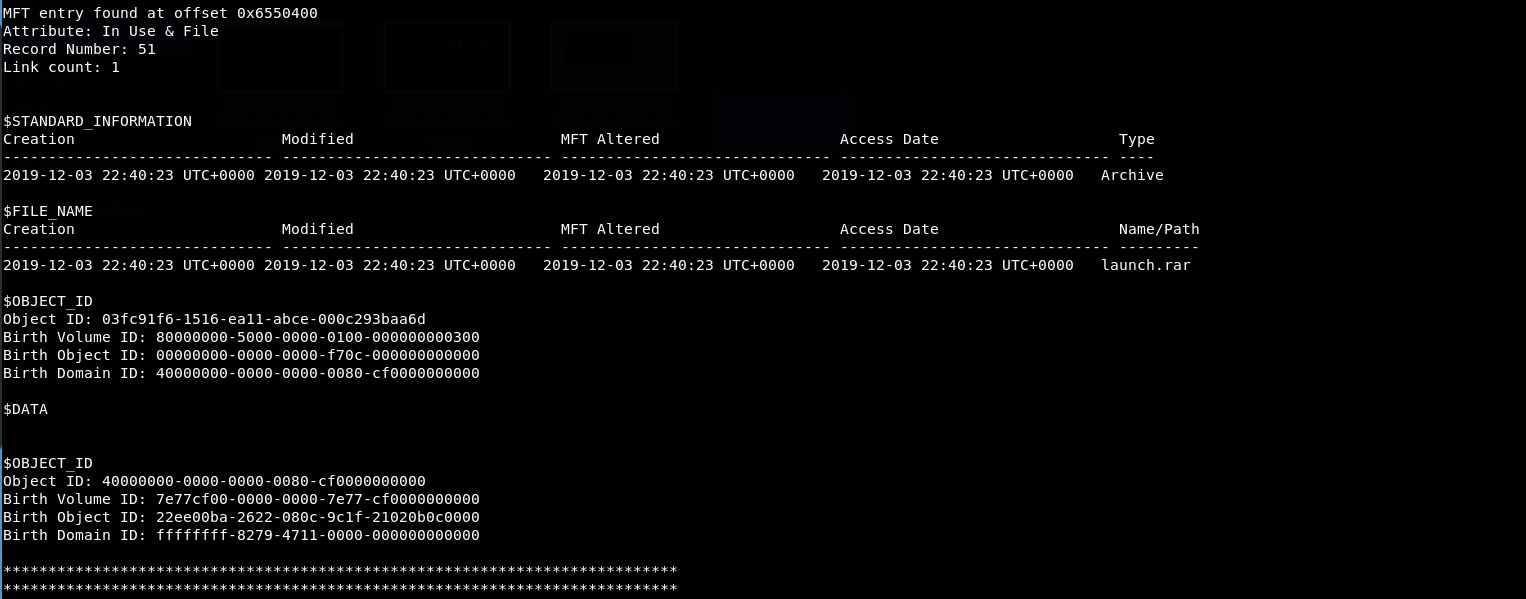
It dumped all the MFT records but we interested in that one as the challenge name is Find the mising meal and there is a deleted file called launch.rar it's not a coincidence so let's jump to that file offset 0x6550400
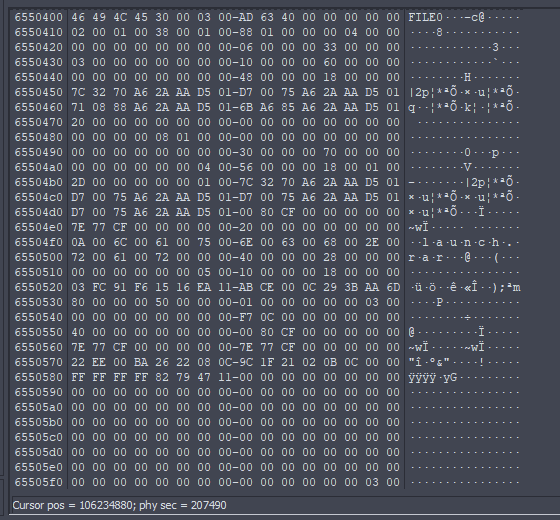
That's the $MFT record for our desired file according to the following table the $MFT record contains a set of attributes that define the file but we only interested in the $DATA attribute .
→ 80 00 00 00
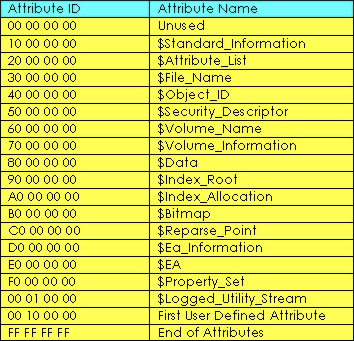
You can notice the start of the data attribute at offset 6550530
We're gonna use this table to help us decode this attribute but I'm gonna jump straight to the data runs because that's what we need here.
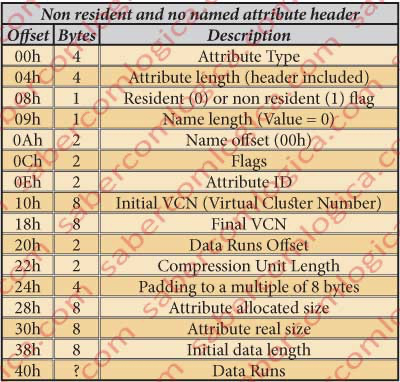
According to the table the data runs starts at 40h from the beginning of the attribute so 0x6550530 + 0x40 = 0x6550570
First we need to understand how can we decode the data run
Data Runs
The Data Runs are a virtual manner of cluster indexation. In this case to index the clusters where the non resident data lives.
The indexation through data runs must be decoded in order to be understood. So, let’s decode the data run for our case which, as we’ve seen, starts at the offset 0x6550570.
At this offset we can see the following bytes chain:
22 EE 00 BA 26 22 08 0C 9C 1F 21 02 0B 0C 00 00Which we are going to decode.
The Byte 22 as to be decomposed in its two digits (half byte) being:
- The lowest order half byte, the 2
2, tells the number of bytes following this one which designate the size in clusters of the data block defined by this data run. It’s 2 bytes, and its value isEE 00meaning by this that the data block has the size of 238 cluster. - The highest order half byte, the
22, tells the number of bytes following the ones which define the size which designate the offset where starts the data block that this data run defines. It’s 2 bytes, the 2 bytes afterEE 00, which are the bytesBA 26, which define the offset in clusters of the data block.
The size of a data run is told by the first byte, i.e. the byte 22 says that, besides it, the data run has 2 + 2 = 4 bytes. After this set another data run starts if the first byte is not 00, case where we are told that there aren’t more data runs. In our case it’s 22, what means that there are more data runs defining the file, It also means that the data of this file is fragmented.
Now that we understand how to decode data runs let's decode the whole chain to reassemble the file
Decoding The Cluster Chain
First Data Run
It starts with 22 so we got 2 bytes for the size and 2 bytes for the offset
- Size:
EE 00we're dealing with a little endian cpu so it's00 EEwhich isEE= 238 clusters - Offset:
0x26BAso we can calculate the offset for the first data segment as follows
0x26BA * 0x1000 + 0x10000 =0x26CA000(where 0x1000 is the cluster size and 0x10000 is the beginning of the partition) - First data segment starts at:
0x26CA000and ends at 0x26CA000 + 0xEE * 0x1000 =0x27B8000
Second Data Run
It starts with 22 also so 2 bytes for size and 2 bytes for offset
- Size:
0xC08= 3080 clusters - Offset:
0x1F9Cso we can calculate the offset for the second data segment as follows
(0x1F9C + 0x26BA) * 0x1000 + 0x10000 =0x4666000(we added the first offset to the second one in the calculations because all the offsets are relevant to the first offset) - Second data segment starts at:
0x4666000and end at 0x4666000 + 0xC08 * 0x1000 =0x526E000
Third Data Run
It starts with 21 so 1 byte for the size and 2 bytes for the offset
- Size:
0x02= 2 clusters - Offset:
0xC0Bso we can calculate the offset for the second data segment as follows
(0xC0B + 0x1F9C + 0x26BA) * 0x1000 + 0x10000 =0x5271000 - Third data segment starts at:
0x5271000and ends at 0x5271000 + 0xC08 * 0x1000 =0x5273000
Then we have 00 00 that means that was the end of our data runs.
Final Touches
Now we can get the hex data from those three data segments and I used this online tool to convert from hex-data to binary file.
We finally got the rar file which contains the following files

Opening the PDF ch13.pdf we got the flag 🙂